
Statistics Simplified is the series to express statistics in layman terms.

When it comes to understanding data, we prefer representing an entire data set using aggregations like count, sum, average, percentages. These aggregations summarize multiple data points into single points. These individual points typically represent the entire datasets, which makes comparisons and decision-making a more straightforward process.
Arguably, the average is the most popular aggregation when it comes to comparisons.
Reason: Average, or also known as the arithmetic mean, is easy to calculate.
How to calculate the average?
We sum the entire data set and then divide it by the count.
Let us take the following sample dataset: 1, 2, 3, 4, 5
Step 1: Calculate sum of all the numbers (1+2+3+4+5) = 15
Step 2: Count all the numbers (1,2,3,4,5) = 5
Step 3: Divide the output of Step 1 by Step 2 (15/5 = 3)
So, in simple words, we can say that the central data point of this dataset is 3. Or, most of the data points are around 3.
The fact that calculating average is an effortless process, and it is a representation of the entire dataset, makes average the most widely used aggregation.
Even Excel has two formula-less ways of calculating average:
Status Bar

Pivot table
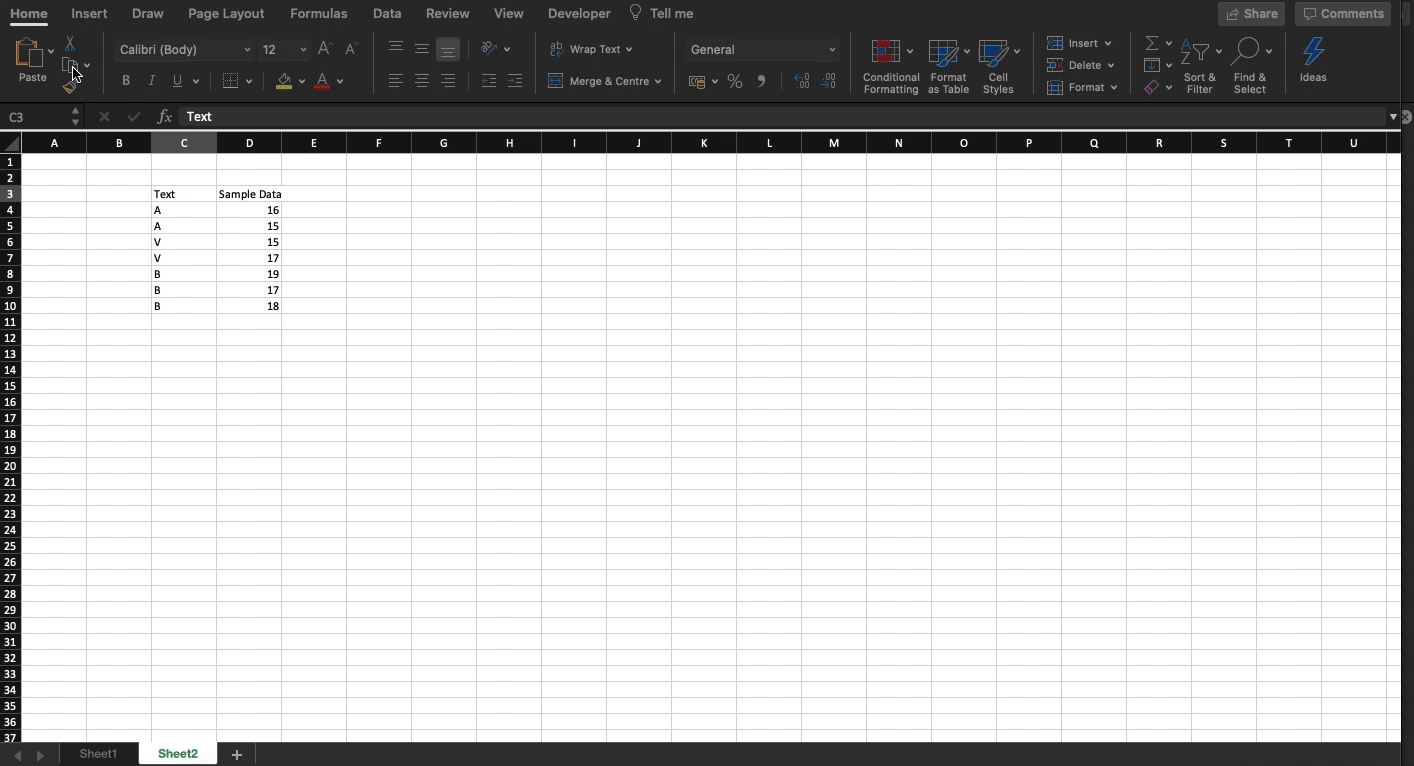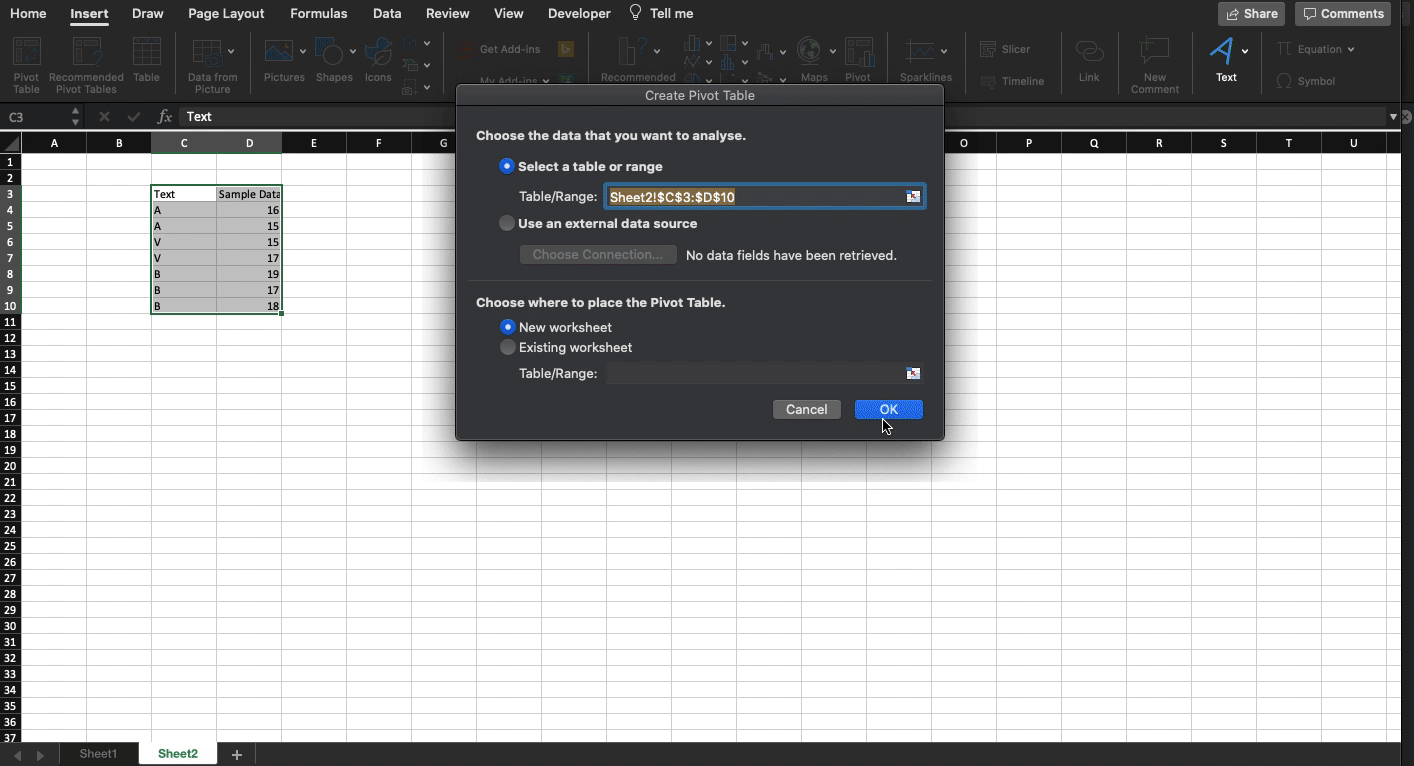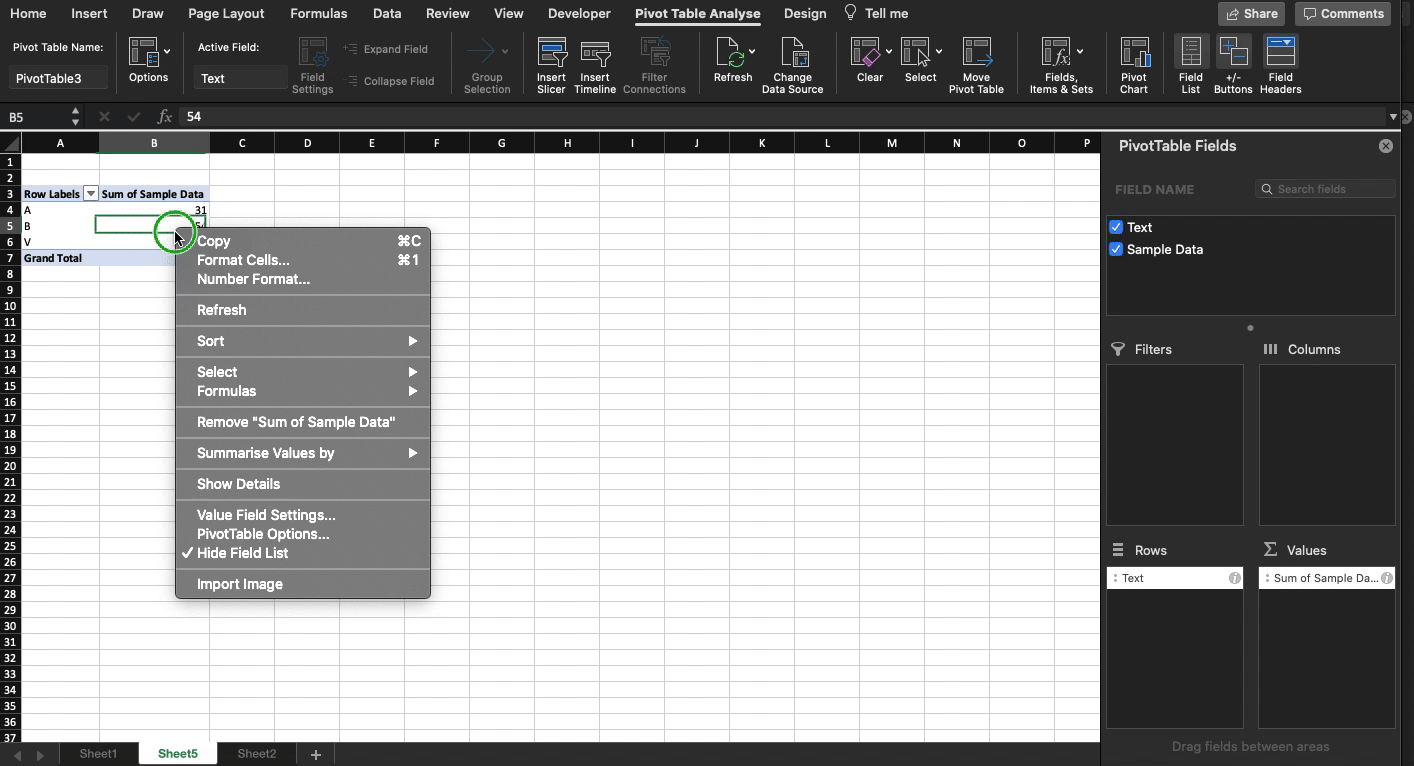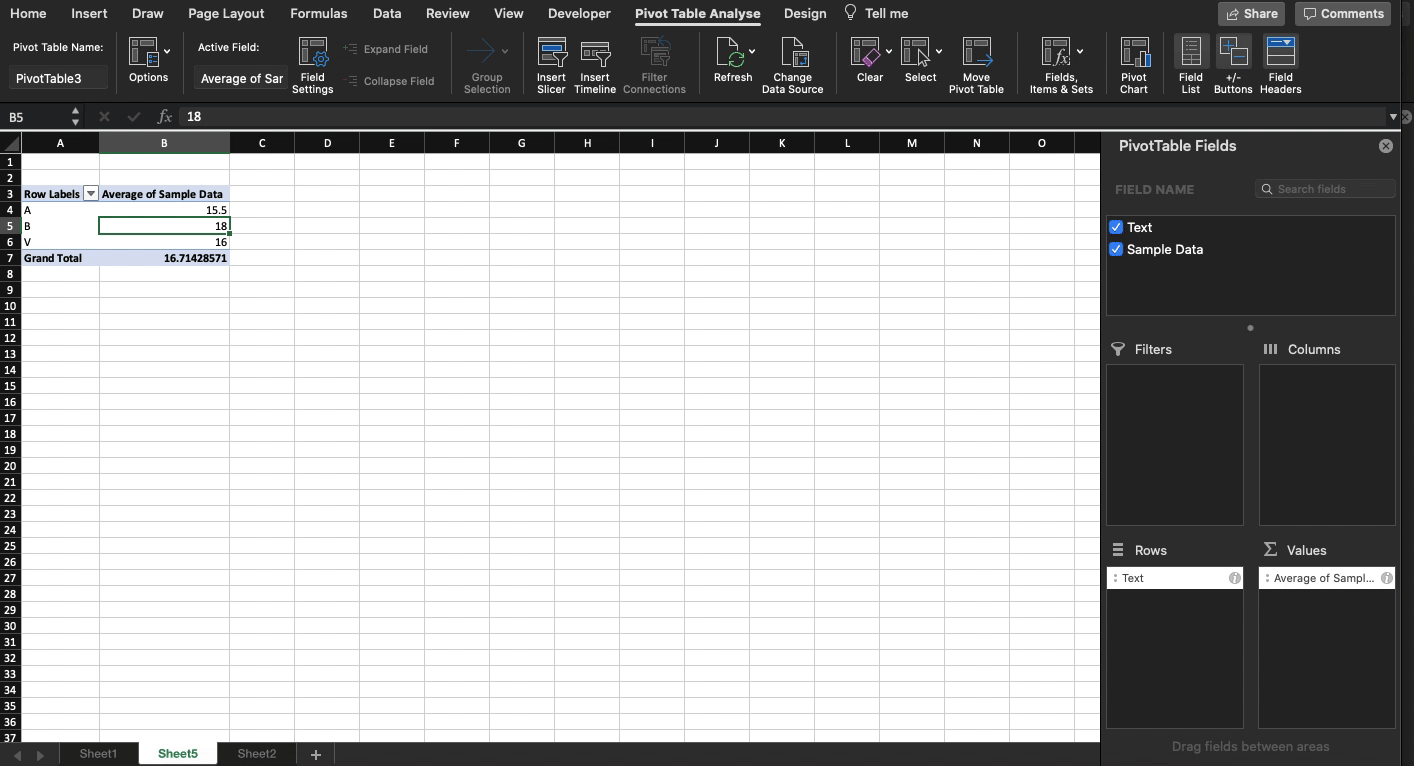
More on Value Field Settings
So what is a Median?
Median is also a representation of the central tendency of the data point. Unlike average, the median is not a calculated value. It is a physical point in the dataset.
Calculating the Median
We sort the data in an order (ascending or descending), and then the middlemost value becomes the median.
Case 1:
When the count of the data set is an odd number
Sample Data: 8, 6, 4, 10, 12
Step 1: Arrange the data in an order -> 4, 6, 8, 10, 12
Step 2: Find the middle number -> 4, 6, 8, 10, 12
Median = 8
Case 2:
When the count of data set is an even number
Sample Data: 8, 6, 4, 10, 12,2
Step 1: Arrange the data in an order -> 2,4, 6, 8, 10, 12
Step 2: Calculate the average of the middle two numbers: 2,4, 6, 8, 10, 12
Median = (6+8)/2 = 7
Formulas in Excel
There are two simple formulas for average and median:
AVERAGE(<array>)
MEDIAN(<array>)
Advantage Median?
Vinci is a data analyst and lives in City A. One of his friends told him that data analysts in City B are getting higher salaries and recommends him to move to City B.
Vinci decided to analyze the wages for data analysts in two cities, A & B. He collected sample data for the two cities and calculated the average.

City A: $ 121,012
City B: $ 258,713
By just looking at this, City B appears to be a prospective location for business analysts as the average salary of City B is 114% higher than City A.
Then, he calculated median salaries for these cities:

City A: $ 122,082
City B: $ 121,511
The median salary of City B is, in fact, slightly lower than City A.
How is this possible? Why are the two characteristics of the central tendency of data telling two different stories?
To find out, Vinci decided to investigate the samples he had used for the analysis.


The salary for one of the samples is significantly higher than the rest of the group, resulting in changing the average value of the group salary.

Extreme values in the data set impacts the average. In such cases, the average can be a misleading representation of the dataset.
However, the median remains unaffected by such data points.


If we exclude Jen’s salary from Sample B and then the average wage of City B comes down to $ 119,260. Now City B does not seem to be lucrative enough, in terms of salary.
He should collect more samples to support his decision to move to City B.
In a nutshell, while comparing performances, we should not wholly rely on averages and include other aggregations. Otherwise, we may end up deciding wrong!
Also see: Trim Mean